Proposed Dual-Conditioned Latent Diffusion Model
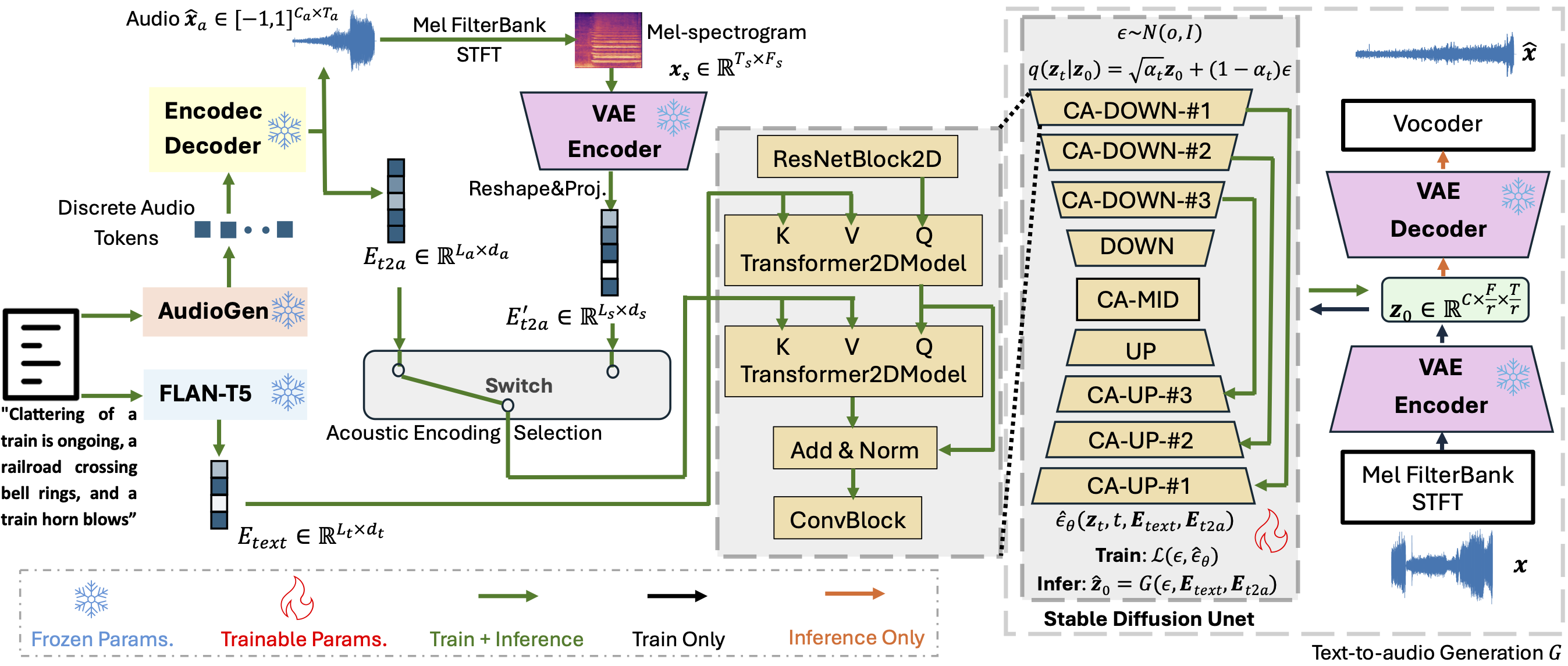 |
Figure 1. Dual-conditioned Latent Diffusion Model Architecture. |
Abstract:
Diffusion models empower the majority of text-to-audio (TTA) generation approaches. Some recent diffusion-based TTA methods use a large text encoder to encode the textual description of the generated audio, which acts as a semantic condition to guide the audio generation. In this work, we build on top of the widely-used diffusion model architecture, and integrate another acoustic condition into the diffusion process. We adopt an auto-regressive generative audio language model that generates audio tokens conditioned on text inputs, then audio tokens can be converted into acoustic latent features as the additional condition representations to improve the audio generation outcome. Consequently, comparing to baseline systems, our dual-conditioned latent diffusion approach delivers better results on most metrics and stays comparable on the rest of results on AudioCaps test set.
Generated audio samples by proposed dual-conditioned diffusion model.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|